نحوه خودکار سازی خوشه بندی کلمات کلیدی SEO با هدف جستجو با پایتون
در مورد هدف جستجو ، از استفاده از یادگیری عمیق گرفته تا استنباط قصد با طبقه بندی متن و شکستن عناوین SERP با استفاده از تکنیک های پردازش زبان طبیعی (NLP) ، تا خوشه بندی بر اساس ارتباط معنایی ، با مزایای توضیح داده شده ، چیزهای زیادی وجود دارد.
نه تنها ما مزایای رمزگشایی قصد جستجو را می دانیم ، بلکه تعدادی از تکنیک ها را نیز در اختیار ما برای مقیاس و اتوماسیون قرار می دهیم.
بنابراین ، چرا ما به مقاله دیگری در مورد خودکار سازی قصد جستجو نیاز داریم؟
هدف جستجو اکنون که جستجوی AI وارد شده است ، مهمتر است.
در حالی که به طور کلی بیشتر در 10 دوره جستجوی لینک آبی بود ، برعکس با فناوری جستجوی هوش مصنوعی صادق است ، زیرا این سیستم عامل ها به طور کلی به منظور ارائه خدمات به حداقل می رسد هزینه های محاسبات (در هر فلاپ) را به حداقل برسانند.
SERP ها هنوز هم بهترین بینش برای هدف جستجو را دارند
تکنیک های تاکنون شامل انجام هوش مصنوعی خود است ، یعنی گرفتن تمام نسخه از عناوین محتوای رتبه بندی برای یک کلمه کلیدی معین و سپس تغذیه آن به یک مدل شبکه عصبی (که شما باید سپس بسازید و آزمایش کنید) یا استفاده از NLP برای کلمات کلیدی خوشه ای.
اگر وقت یا دانش لازم برای ساخت هوش مصنوعی خود را ندارید یا از AI AI API باز می کنید ، چه می کنید؟
در حالی که شباهت Cosine به عنوان پاسخی برای کمک به متخصصان سئو در جهت مشخص کردن مباحث مربوط به طبقه بندی و ساختارهای سایت مورد توجه قرار گرفته است ، من هنوز هم معتقدم که خوشه بندی جستجو توسط نتایج SERP روشی بسیار برتر است.
دلیل این امر این است که هوش مصنوعی بسیار مشتاق است که نتایج خود را بر روی SERP ها و به دلایل خوبی قرار دهد – این بر روی رفتارهای کاربر الگوبرداری شده است.
روش دیگری وجود دارد که از هوش مصنوعی بسیار Google برای انجام کار برای شما استفاده می کند ، بدون اینکه بخواهید تمام محتوای SERPS را خراش دهید و یک مدل هوش مصنوعی بسازید.
بیایید فرض کنیم که Google URL های سایت را با توجه به احتمال رضایت از مطالب رضایت از پرس و جو کاربر به ترتیب نزولی رتبه بندی می کند. از این رو نتیجه می گیرد که اگر هدف برای دو کلمه کلیدی یکسان باشد ، احتمالاً SERP ها مشابه هستند.
سالهاست که بسیاری از متخصصان سئو نتایج SERP را برای کلمات کلیدی برای استنباط (یا به اشتراک گذاشته شده) جستجو می کنند و قصد دارند در صدر به روزرسانی های اصلی بمانند ، بنابراین این چیز جدیدی نیست.
ارزش افزوده در اینجا اتوماسیون و مقیاس بندی این مقایسه است و هم سرعت و هم دقت بیشتری را ارائه می دهد.
نحوه خوشه کلمات کلیدی با استفاده از قصد در مقیاس با استفاده از پایتون (با کد)
با فرض اینکه SERP های خود را در بارگیری CSV داشته باشید ، بیایید آن را به نوت بوک Python خود وارد کنیم.
1. لیست را به نوت بوک پایتون خود وارد کنید
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
در زیر پرونده SERPS اکنون به یک Pandas Dataframe وارد شده است.
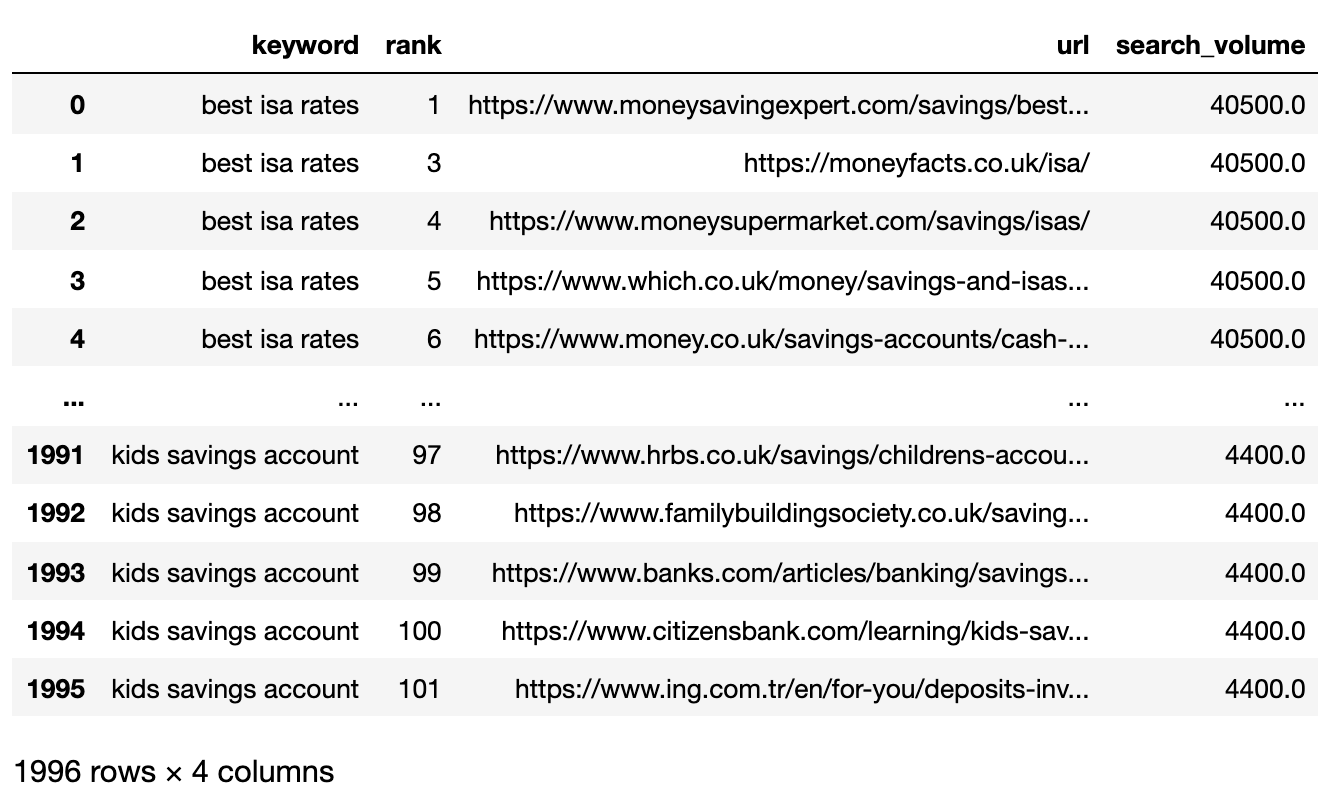 تصویر از نویسنده ، آوریل 2025
تصویر از نویسنده ، آوریل 20252. داده ها را برای صفحه 1 فیلتر کنید
ما می خواهیم نتایج صفحه 1 هر SERP را بین کلمات کلیدی مقایسه کنیم.
ما DataFrame را به Mini Worder DataFrames تقسیم می کنیم تا عملکرد فیلتر را قبل از نوترکیب در یک DataFrame واحد اجرا کنیم ، زیرا می خواهیم در سطح کلمه کلیدی فیلتر کنیم:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] 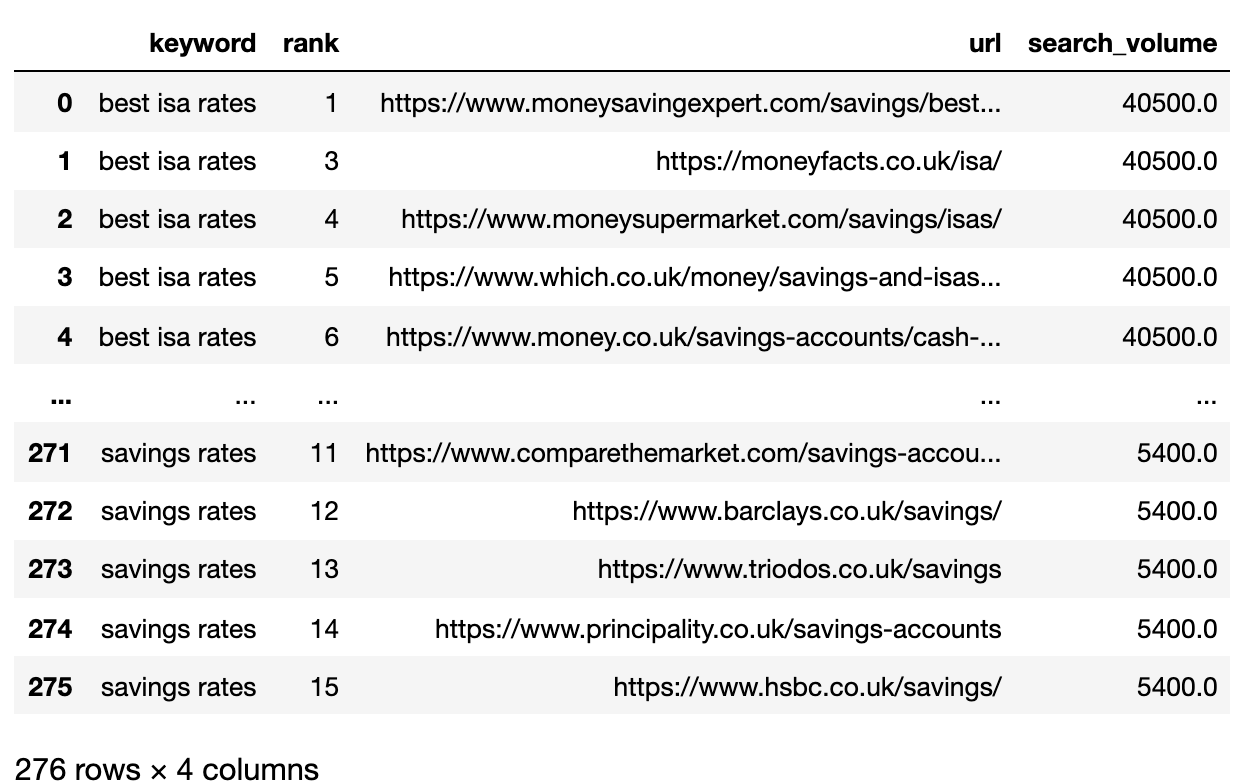 تصویر از نویسنده ، آوریل 2025
تصویر از نویسنده ، آوریل 20253. Convert Ranking URLs To A String
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
در زیر SERP فشرده شده در یک خط واحد برای هر کلمه کلیدی.
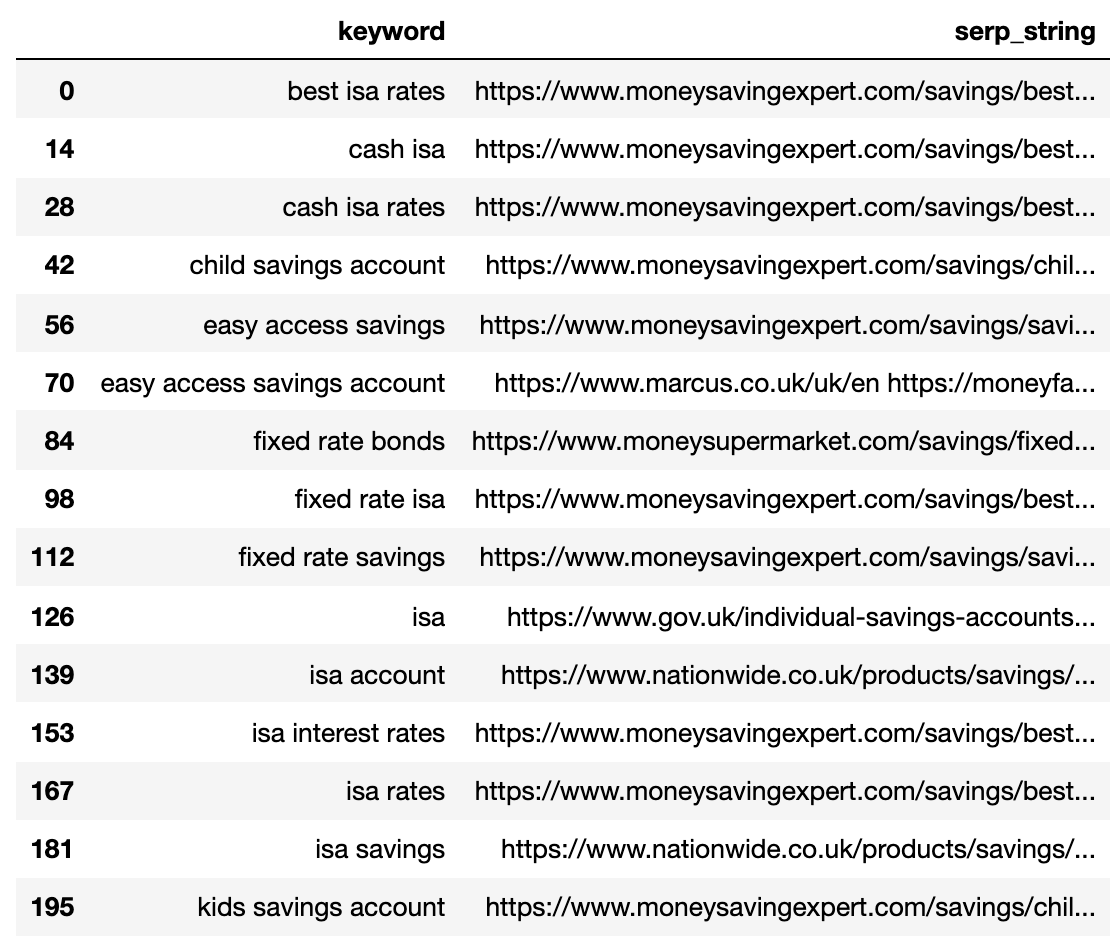 تصویر از نویسنده ، آوریل 2025
تصویر از نویسنده ، آوریل 20254. فاصله SERP را مقایسه کنید
برای انجام مقایسه ، اکنون به هر ترکیبی از کلمات کلیدی SERP که با جفت های دیگر جفت شده است ، نیاز داریم:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
اکنون ما نام موضوع بالقوه ، شباهت SERP کلمات کلیدی را داریم و حجم هر یک را جستجو می کنیم.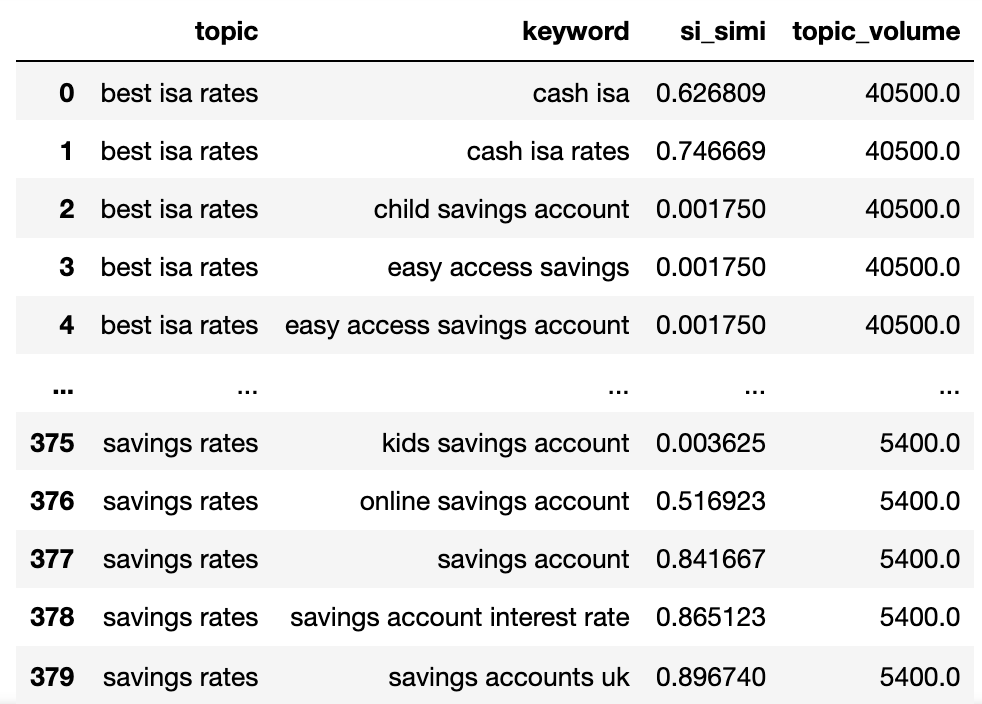
توجه داشته باشید که کلمه کلیدی و کلمه کلیدی_B به ترتیب به موضوع و کلمه کلیدی تغییر نام داده اند.
اکنون می خواهیم با استفاده از تکنیک Lambda ، ستون های موجود در DataFrame را تکرار کنیم.
تکنیک Lambda روشی کارآمد برای تکرار ردیف ها در یک Pandas Dataframe است زیرا ردیف ها را بر خلاف عملکرد .iterrows () تبدیل می کند.
اینجا می رود:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) در زیر یک فرهنگ لغت حاوی تمام کلمات کلیدی که توسط قصد جستجو در گروه های شماره گذاری شده جمع شده اند ، نشان می دهد:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}بیایید آن را به یک dataframe بچسبانیم:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
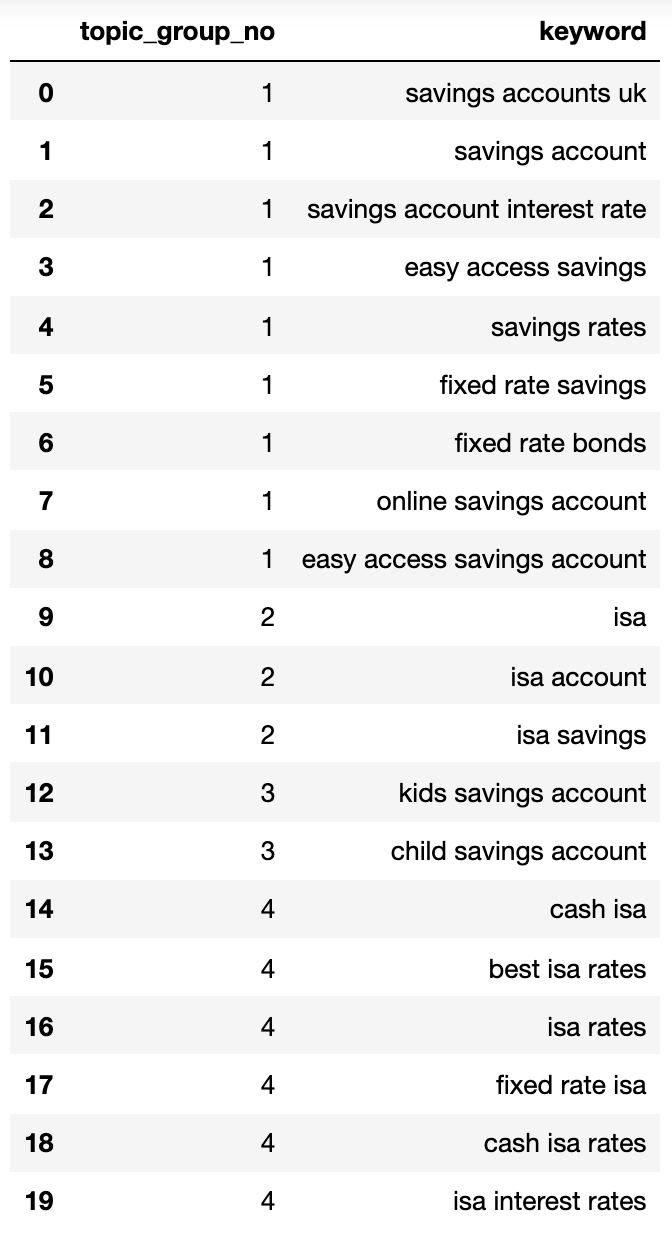 تصویر از نویسنده ، آوریل 2025
تصویر از نویسنده ، آوریل 2025گروه های هدف جستجو در بالا تقریب خوبی از کلمات کلیدی در داخل آنها را نشان می دهند ، چیزی که احتمالاً یک متخصص سئو به آن دست می یابد.
اگرچه ما فقط از مجموعه کوچکی از کلمات کلیدی استفاده کردیم ، بدیهی است که این روش می تواند به هزاران نفر (اگر بیشتر نباشد) مقیاس بندی شود.
فعال کردن خروجی ها برای بهتر کردن جستجوی شما
البته موارد فوق را می توان با استفاده از شبکه های عصبی بیشتر ، پردازش محتوای رتبه بندی برای خوشه های دقیق تر و نامگذاری گروه خوشه ای ، همانطور که برخی از محصولات تجاری موجود در آنجا انجام می دهند ، انجام شود.
در حال حاضر ، با این خروجی ، می توانید:
- این را در سیستم های داشبورد SEO خود قرار دهید تا روندها و گزارش های سئو خود را معنی دار تر کنید.
- با ساختن حساب های Google Ads خود با هدف جستجو برای نمره با کیفیت بالاتر ، کمپین های جستجوی پرداخت شده بهتر را بسازید.
- URL های جستجوی تجارت الکترونیک را با استفاده از بازه زمانی ادغام کنید.
- طبقه بندی سایت خرید را با توجه به قصد جستجو به جای یک کاتالوگ محصول معمولی ، ساختار دهید.
من مطمئن هستم که برنامه های بیشتری وجود دارد که من به آنها اشاره نکرده ام – احساس راحتی کنید که در مورد موارد مهمی که قبلاً ذکر نکرده ام اظهار نظر کنید.
در هر صورت ، تحقیقات کلمه کلیدی سئو شما فقط کمی مقیاس پذیر ، دقیق تر و سریعتر شده است!
برای استفاده شخصی خود کد کامل را در اینجا بارگیری کنید.
منابع بیشتر:
تصویر برجسته: Buch and Bee/Shutterstock
