اطلاعات بیشتر از +546000 مرور کلی هوش مصنوعی
پس از اولین تجزیه و تحلیل من از +546000 مرورهای هوش مصنوعی، به سه سوال عمیق تر پرداختم:
- دادههای رایج خزیدن و بررسیهای اجمالی هوش مصنوعی چگونه به هم مرتبط هستند؟
- نیت کاربر چگونه مرورهای هوش مصنوعی را تغییر می دهد؟
- چگونه 20 موقعیت برتر برای دامنه هایی که در جستجوی ارگانیک رتبه بندی می شوند و در AIO استناد می شوند، تجزیه می شوند؟
دادههای رایج Crawl و مرورهای کلی هوش مصنوعی چگونه به هم مرتبط هستند؟
گنجاندن خزیدن معمولی بر روی دید AIO به اندازه ترافیک ارگانیک خالص تأثیر نمی گذارد.
Common Crawl، یک سازمان غیرانتفاعی که در وب می خزند و داده ها را به صورت رایگان ارائه می کند، بزرگترین منبع داده آموزش هوش مصنوعی مولد است.
برخی از سایتها، مانند Blogspot، صفحات بسیار بیشتری را نسبت به سایرین ارائه میکنند و این سوال را ایجاد میکنند که آیا این به آنها برتری در پاسخهای LLM میدهد.
نتیجه: من نمیدانستم که آیا سایتهایی که صفحات بیشتری نسبت به سایرین ارائه میدهند، در مرورهای هوش مصنوعی نیز دید بیشتری خواهند داشت. معلوم شد که درست نیست.
من 500 دامنه برتر را بر اساس سهم صفحه در Common Crawl با 30000 دامنه برتر در مجموعه داده خود مقایسه کردم و یک همبستگی ضعیف 0.179 پیدا کردم.
دلیل آن این است که گوگل احتمالاً به Common Crawl برای آموزش و اطلاع رسانی AI Overviews متکی نیست، بلکه به فهرست خود متکی است.
 اعتبار تصویر: کوین ایندیگ
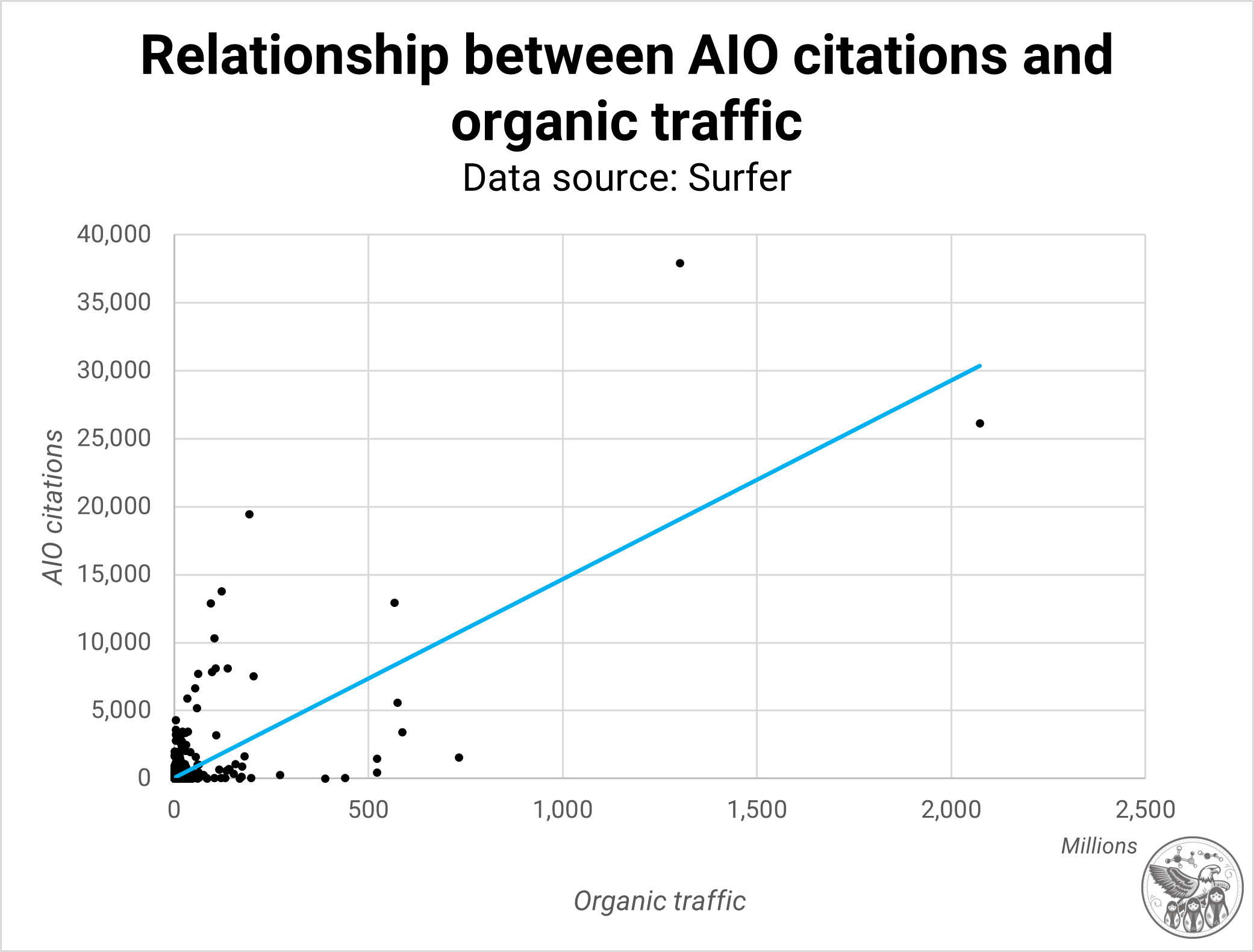
اعتبار تصویر: کوین ایندیگسپس رابطه بین 3000 دامنه برتر توسط ترافیک ارگانیک از Semrush و 30000 دامنه برتر در مجموعه داده خود را تجزیه و تحلیل کردم و یک رابطه قوی 0.714 پیدا کردم.
به عبارت دیگر، دامنههایی که ترافیک ارگانیک زیادی دریافت میکنند، به احتمال زیاد در مرورهای هوش مصنوعی بسیار قابل مشاهده هستند.
به نظر می رسد AIO به طور فزاینده ای به آنچه در جستجوی ارگانیک کار می کند پاداش می دهد، اما برخی از معیارها هنوز بسیار مجزا هستند.
مهم است که بگوییم چند سایت این رابطه را مخدوش می کنند.
هنگام فیلتر کردن ویکیپدیا و یوتیوب، این رابطه به همبستگی 0.485 کاهش مییابد – هنوز قوی است اما نسبت به این دو غول پایینتر است.
این همبستگی با حذف سایتهای بزرگتر تغییر نمیکند، و این نکته را تقویت میکند که انجام کارهایی که در جستجوی ارگانیک کار میکنند، تأثیر زیادی بر مرورهای هوش مصنوعی دارد.
همانطور که در پست قبلی نوشتم:
رتبه بالاتر در نتایج جستجو مطمئناً شانس قابل مشاهده شدن در AIOها را افزایش می دهد، اما این تنها عامل نیست.
در نتیجه، شرکتها میتوانند ربات Common Crawl را در robots.txt حذف کنند، اگر نمیخواهند در مجموعه دادههای عمومی (و هوش مصنوعی ژنتیکی مانند Chat GPT) ظاهر شود و همچنان در نمای کلی هوش مصنوعی گوگل بسیار قابل مشاهده باشد.
چگونه قصد کاربر مرورهای هوش مصنوعی را تغییر می دهد؟
هدف کاربر شکل و محتوای AIO ها را شکل می دهد.
در تجزیه و تحلیل قبلی خود، به این نتیجه رسیدم که تطابق دقیق پرس و جو به سختی اهمیت دارد:
داده ها نشان می دهد که تنها 6 درصد از AIO ها حاوی عبارت جستجو هستند.
این عدد در SGE کمی بالاتر است، 7٪، و در AIO های زنده کمتر، با 5.1٪. در نتیجه، ملاقات با هدف کاربر در محتوا بسیار مهمتر از آن چیزی است که ما تصور می کردیم. این نباید تعجب آور باشد زیرا هدف کاربر برای سالها یک الزام کلیدی رتبهبندی در سئو بوده است، اما دیدن دادهها تکان دهنده است.
محاسبه دقیق قصد کاربر (غالب) برای همه 546000 پرس و جو بسیار محاسباتی خواهد بود، بنابراین من به انتزاعات رایج اطلاعاتی، محلی و تراکنشی نگاه کردم.
انتزاع ها هنگام بهینه سازی محتوا کمتر مفید هستند، اما هنگام مشاهده داده های انبوه، خوب هستند.
من خوشه بندی کردم:
- پرس و جوهای اطلاعاتی در مورد کلمات سوالی مانند “چی”، “چرا”، “وقتی” و غیره.
- پرس و جوهای معاملاتی پیرامون عباراتی مانند «خرید»، «دانلود»، «سفارش» و غیره.
- جستجوهای محلی در اطراف «نزدیک»، «نزدیک» یا «نزدیک من».
 اعتبار تصویر: کوین ایندیگ
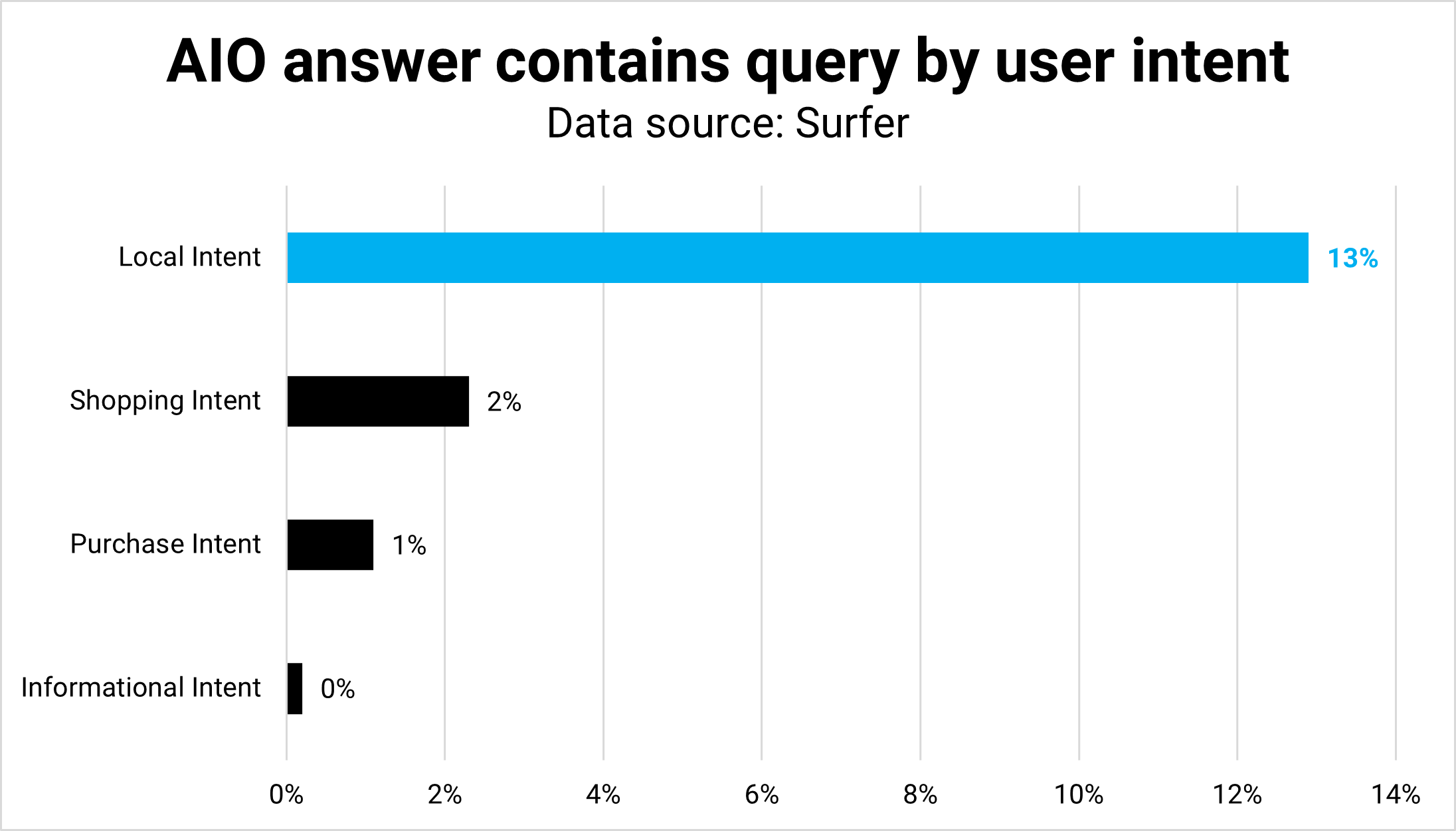
اعتبار تصویر: کوین ایندیگنتیجه: تفاوت های قصد کاربر در شکل و عملکرد منعکس می شود. میانگین طول (تعداد کلمات) تقریباً در همه مقاصد به جز محلی برابر است، که منطقی است زیرا کاربران به جای متن، فهرستی از مکانها را میخواهند.
به طور مشابه، AIOهای خرید اغلب لیستی از محصولات با کمی زمینه هستند، مگر اینکه سوالات مربوط به خرید باشند.
پرس و جوهای محلی بیشترین میزان تطابق دقیق بین پرس و جو و پاسخ را دارند. پرس و جوهای اطلاعاتی کمترین را دارند.
درک و ارضای نیت کاربر برای سؤالات دشوارتر است، اما در عین حال مهم تر از مثلاً Featured Snippets قابل مشاهده در AIO است.
چگونه 20 موقعیت ارگانیک برتر تجزیه می شوند؟
در آخرین تحلیلم، متوجه شدم که تقریباً 60 درصد از URL هایی که در AIOها و نتایج جستجوی ارگانیک ظاهر می شوند، خارج از 20 موقعیت برتر قرار دارند.
برای این یادداشت، من 20 مورد برتر را بیشتر تقسیم کردم تا بفهمم آیا AIOها به احتمال بیشتری آدرسهای اینترنتی را در موقعیتهای بالاتر ذکر میکنند یا خیر.
 اعتبار تصویر: کوین ایندیگ
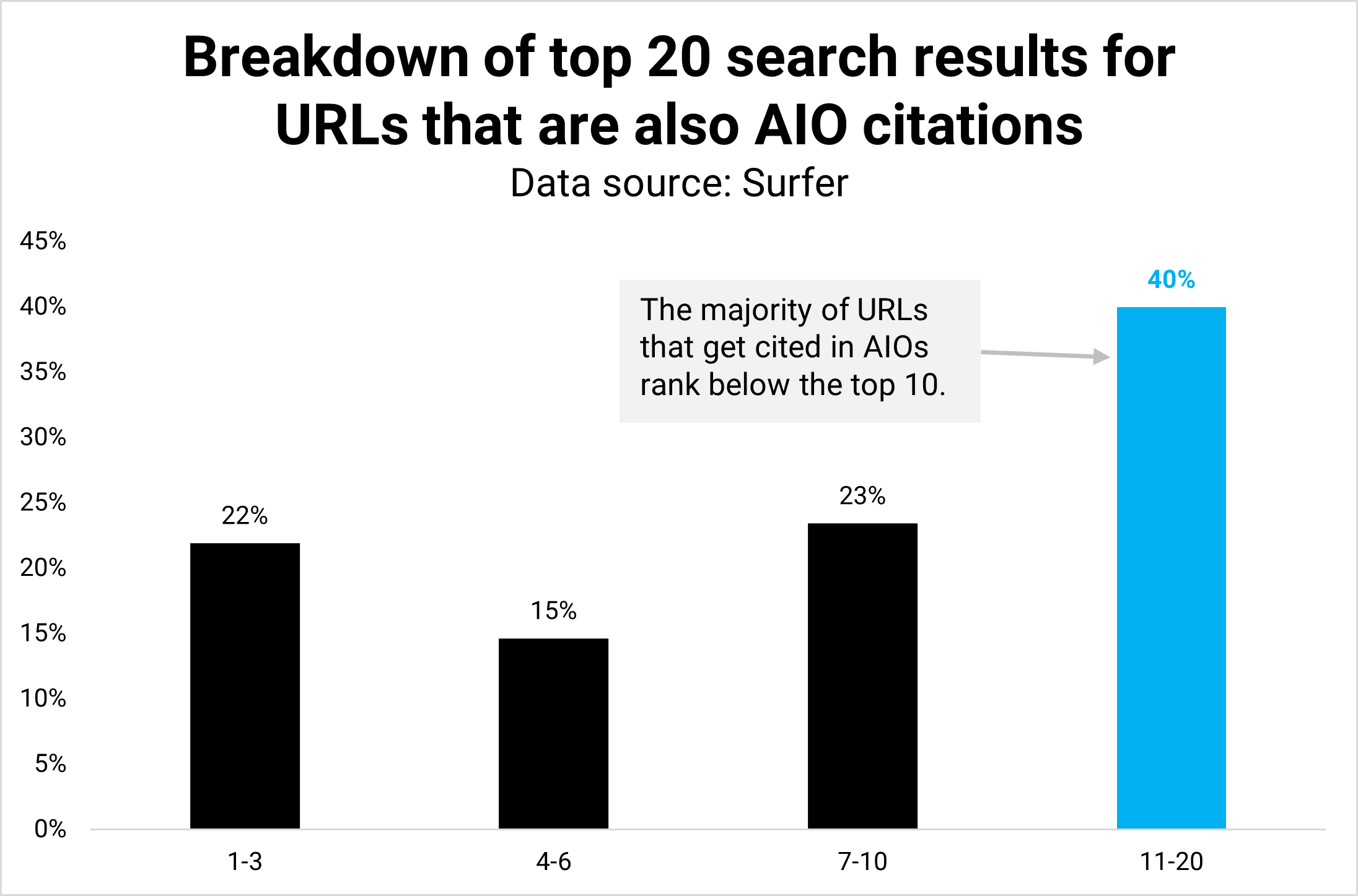
اعتبار تصویر: کوین ایندیگنتیجه: به نظر می رسد 40٪ از URL ها در AIO ها در موقعیت های 11-20 قرار می گیرند و تنها نیمی از آنها (21.9٪) در رتبه 3 برتر قرار دارند.
اکثریت، 60 درصد از URL های ذکر شده در AIO ها، همچنان در صفحه اول نتایج ارگانیک قرار می گیرند و این نکته را تقویت می کند که رتبه ارگانیک بالاتر منجر به شانس بالاتری برای استناد در AIO ها می شود.
با این حال، دادهها همچنین نشان میدهند که حضور در AIOهایی با رتبه ارگانیک پایینتر بسیار غیرممکن است.
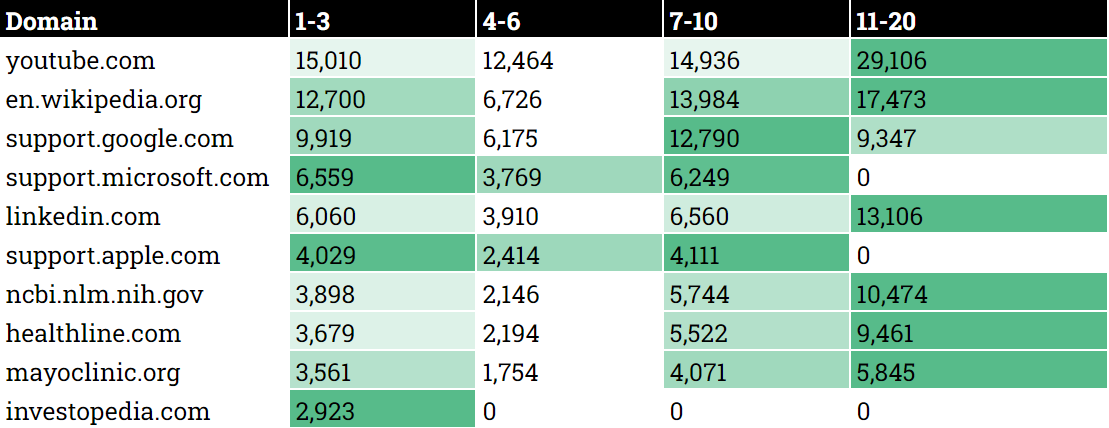 جایی که 20 دامنه برتر قابل مشاهده در AIOها و نتایج جستجو رتبه بندی می شوند (اعتبار تصویر: کوین ایندیگ)
جایی که 20 دامنه برتر قابل مشاهده در AIOها و نتایج جستجو رتبه بندی می شوند (اعتبار تصویر: کوین ایندیگ)سناریوها
من با مشتریانم کار خواهم کرد تا با هدف کاربر AIO مطابقت داشته باشم، بینش منحصربهفردی ارائه کنم و قالب را تنظیم کنم. من گزینههایی را برای پیشرفت نمای کلی هوش مصنوعی میبینم که در ماهها و سالهای آینده آنها را با دادهها ردیابی و تأیید خواهم کرد.
گزینه 1: AIOها بیشتر به نتایج ارگانیک با رتبه برتر متکی هستند و قبل از اینکه کاربران نیاز به کلیک روی وب سایت ها داشته باشند، اهداف اطلاعاتی بیشتری را برآورده می کنند. اکثر کلیکهایی که روی سایتها فرود میآیند از سوی کاربرانی است که قصد خرید دارند یا قصد خرید دارند.
گزینه 2: AIO ها همچنان به ارائه پاسخ از نتایج متنوع ادامه می دهند و شانس کمی برای کاربران باقی می گذارند که همچنان به نتایج رتبه های برتر مراجعه کنند، البته در مقادیر بسیار کمتر.
روی کدام سناریو شرط بندی می کنید؟
تصویر ویژه: پائولو بوبیتا/ژورنال موتور جستجو
